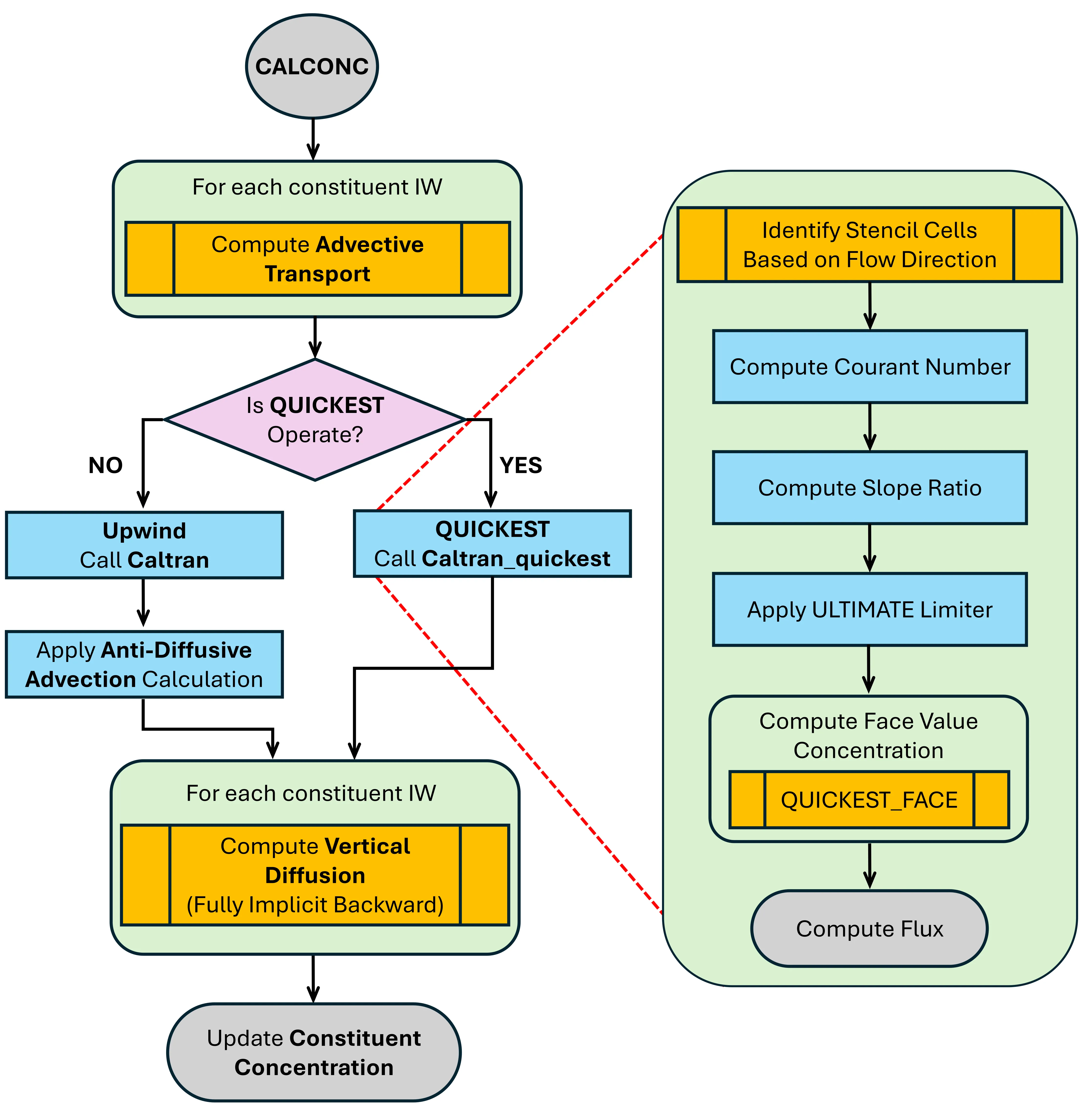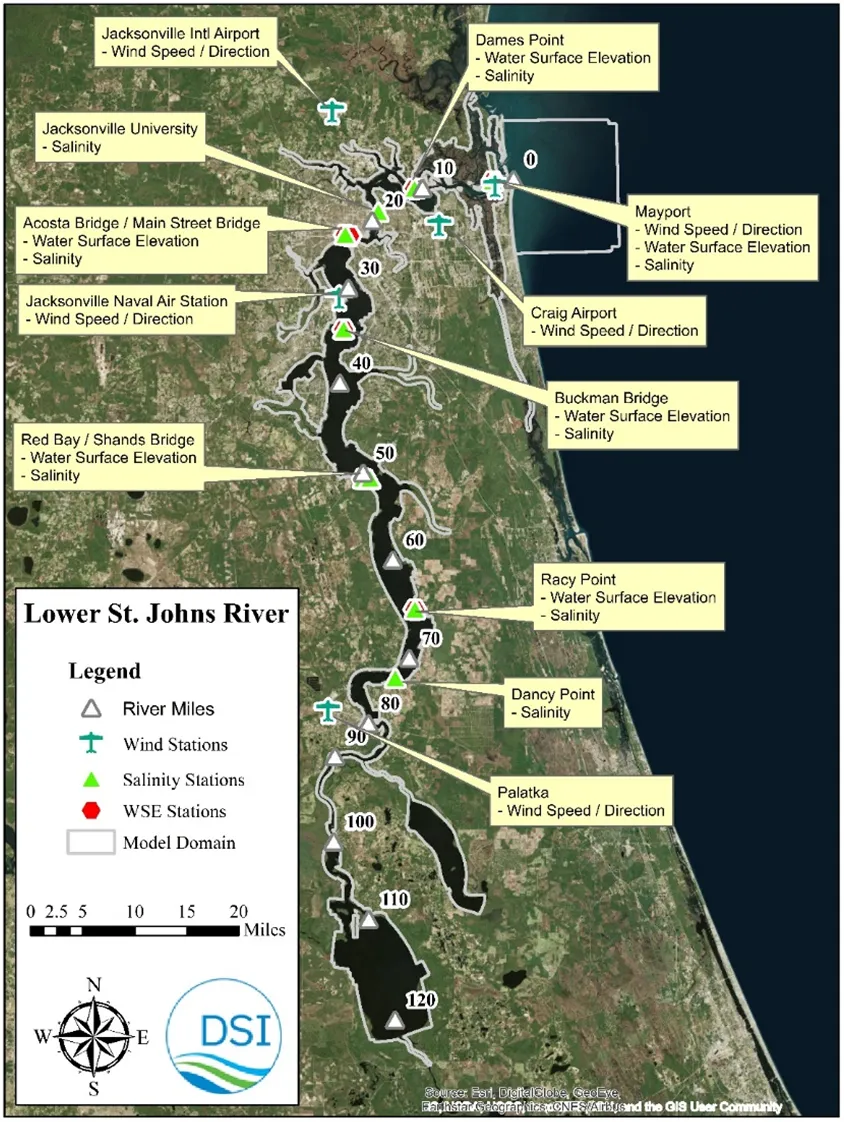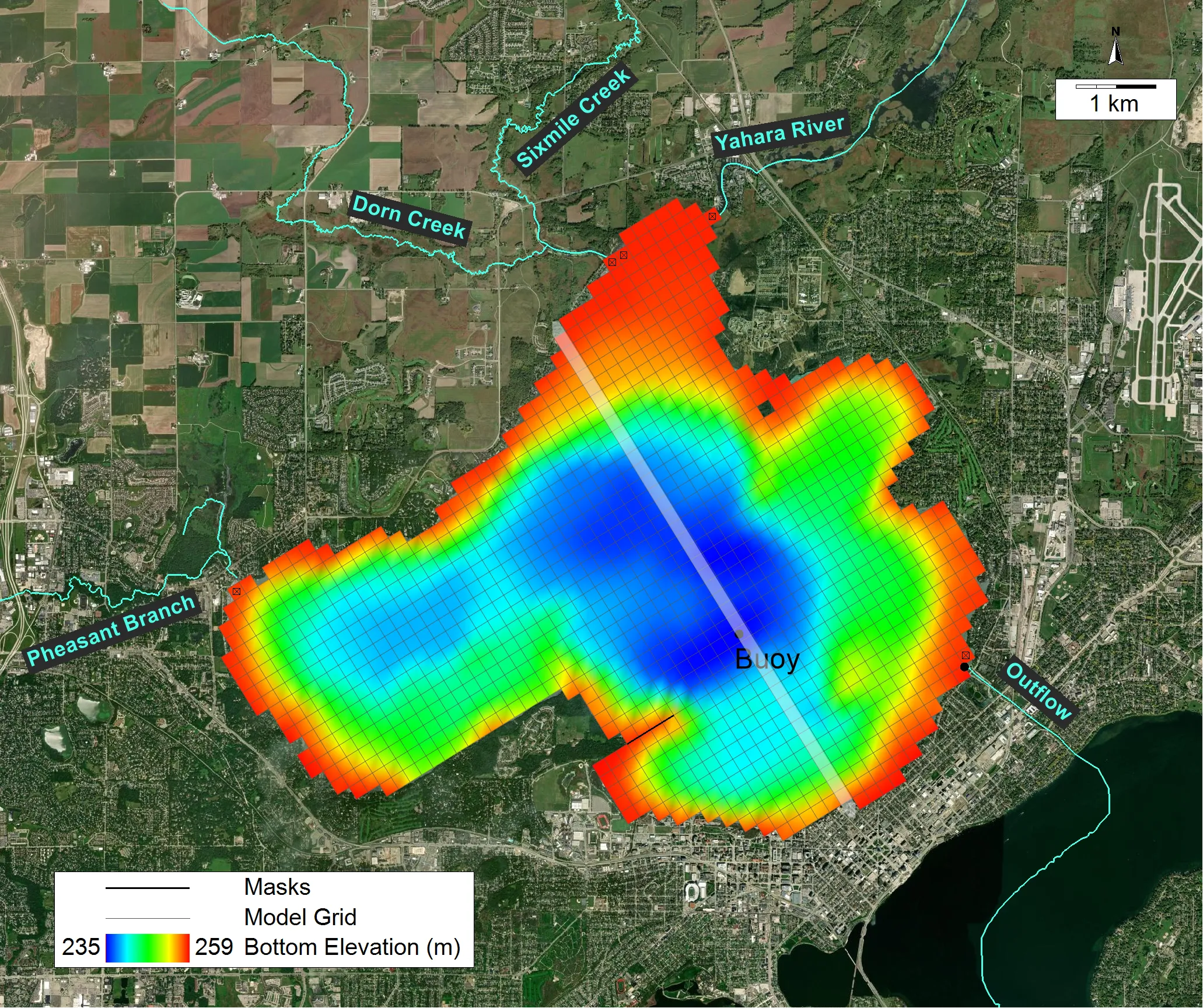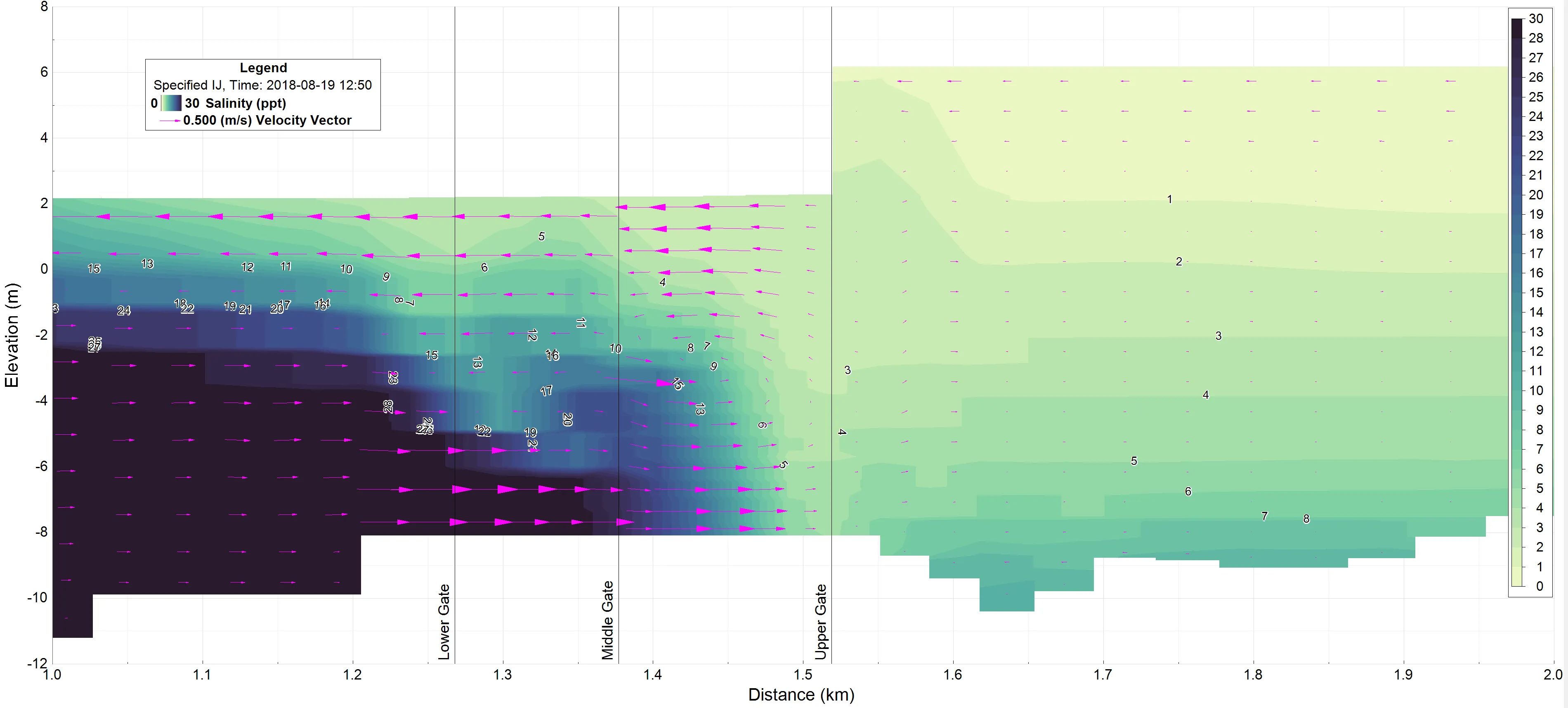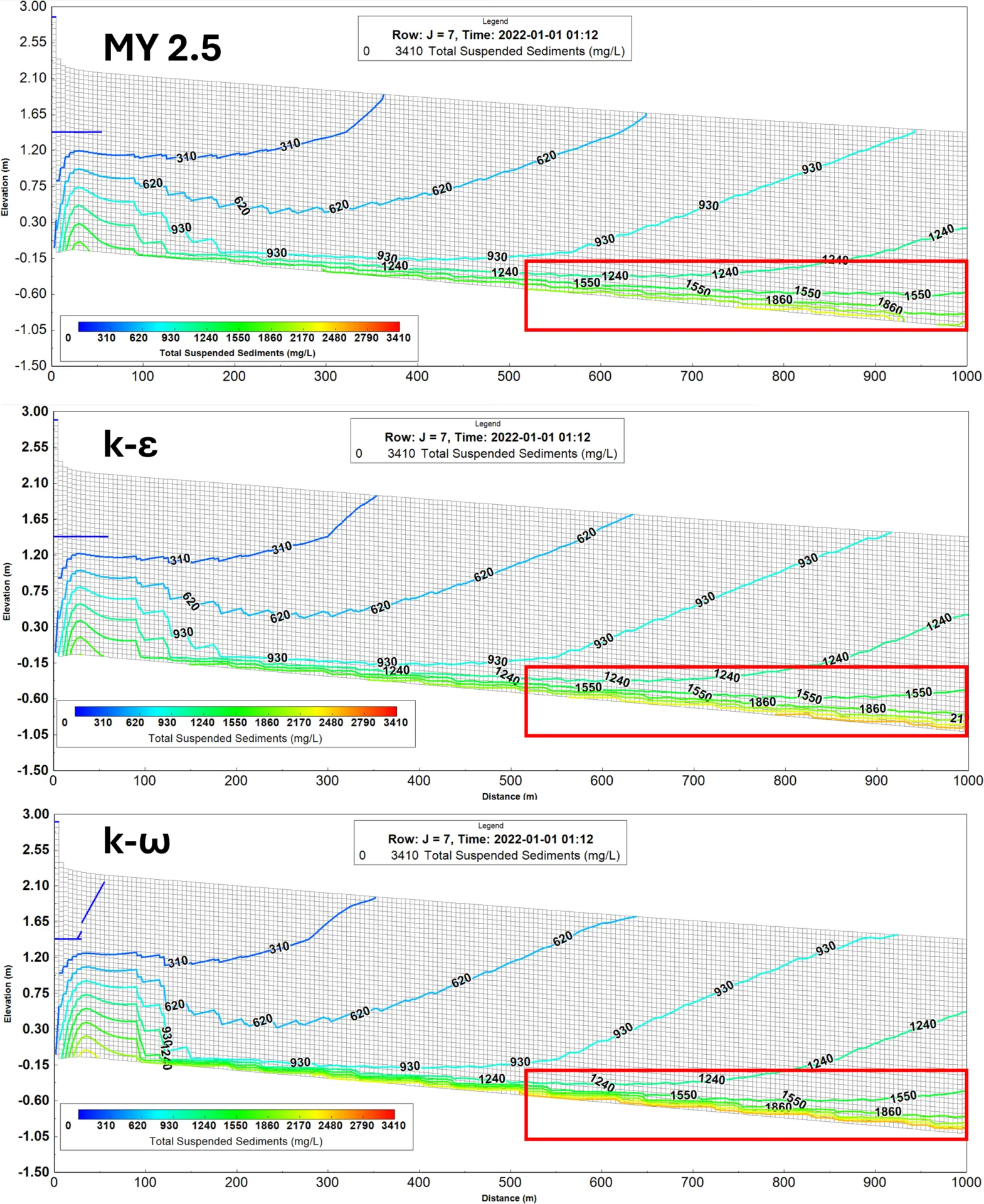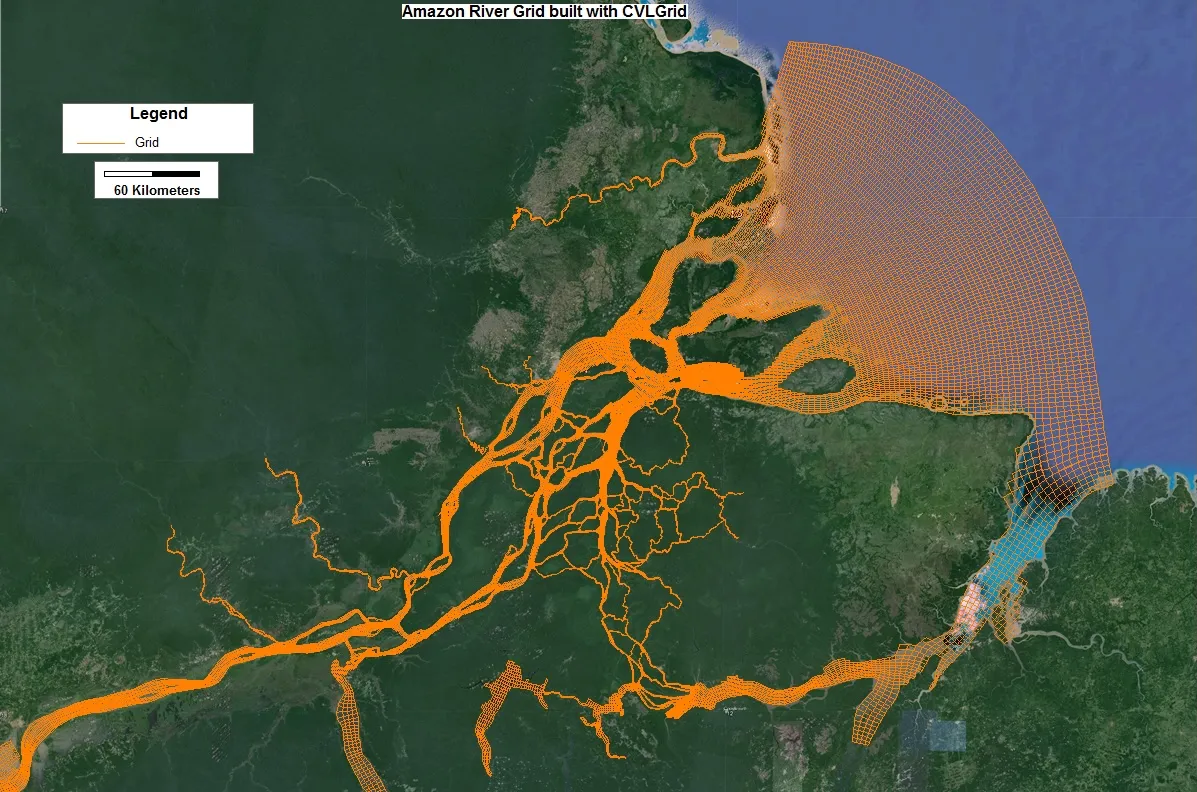





















Efficiency
EE was designed with the end user in mind. Our GUI eliminates weeks to months of effort determining which input files are needed, file formatting and how to post process model results. EFDC+ allows the user to access the full computing power of multi-core systems, on site clusters or cloud based High Performance Computing (HPC) clusters to run simulations faster than ever. This saves resources and allows the modeler to pursue solutions with confidence.